距4月14日雷军官宣杀入大模型不到4个月,小米大模型终于首次曝光,并交出了一份初步成绩单!
多方消息显示,小米大模型MiLM-6B现身C-Eval、CMMLU大模型评测榜单。
根据GitHub项目页给出的信息,MiLM-6B(下称:小米大模型)是由小米开发的一个大规模预训练语言模型,参数规模为64亿。
相关页面显示,小米大模型在C-Eval榜单中排名第9、同参数量级排名第1,在CMMLU中文向大模型排名第1。
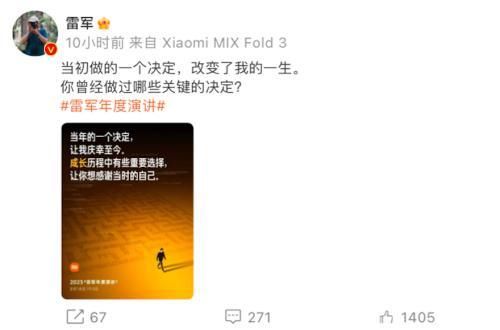
值得一提的是,雷军将于下周一(8月14日)晚间的新品发布会上,发表年度演讲。
本次演讲以“成长”为主题,雷军发布的微博透露,“当初做的一个决定,改变了我的一生。”而且,这个决定让他庆幸至今。
外界猜测,雷军年度演讲的内容,除了与小米造车相关,或许还将与小米筹备已久的大模型有关。
小米大模型取得双“第一”,下周一或亮相
C-Eval榜单,全称C-Eval全球大模型综合性考试测试榜,是由清华大学、上海交通大学和爱丁堡大学合作构建的中文语言模型综合性考试评估套件。
该套件覆盖人文、社科、理工、其他专业四个大方向,包括52个学科,涵盖微积分、线性代数等多个知识领域。共有13948道中文知识和推理型题目,难度分为中学、本科、研究生、职业等四个考试级别,能够更加全面的对模型的语言处理能力进行评估,对中文社区语言大模型的研发有着很好的参考价值。
具体而言,在C-Eval评估中,小米大模型的平均分为60.2,在STEM、社会科学、人文科学、其他这四个类别中,均取得了不错的表现。
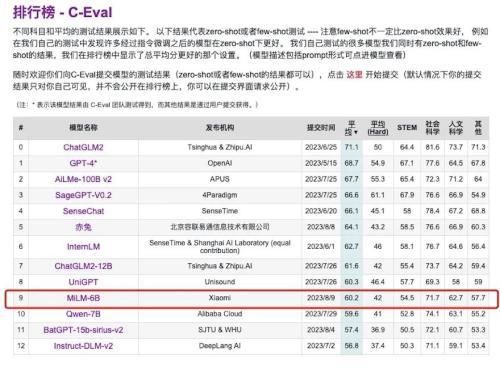
来源:C-Eval截图
其中,在STEM(科学、技术、工程和数学教育)全部20个科目中,小米大模型得分54.5,在计量师、物理、化学、生物等多个项目中获得了较高的准确率;在10个社会科学科目中,小米大模型得分71.7,在教育学和地理外的所有科目中,获得了较为理想的准确率;在11个人文科学科目中,小米大模型得分62.7,在历史与法律基础上,获得了不错的准确率;在其他分类下,小米大模型则得分57.7。
整体而言,小米大模型在法学、数学、编程、概率论、离散数学等科目上的表现,仍然有明显进步空间。
CMMLU,则是由MBZUAI、上海交通大学、微软亚洲研究院合作完成的,一个全面的中文大模型基准。它涵盖了67个主题,涉及自然科学、社会科学、工程、人文、以及常识等,可以全面地评估大模型在中文知识储备和语言理解上的能力。
在CMMLU中文向大模型评估中,小米大模型在zero-shot和five-shot测试中的平均分分别为60.37和57.17,表现出良好的知识和推理能力。
在zero-shot测试中,小米大模型在人文学科得分63.49,社会科学得分66.2,其他得分62.14,中国特定主题得分62.07,平均分为60.37。
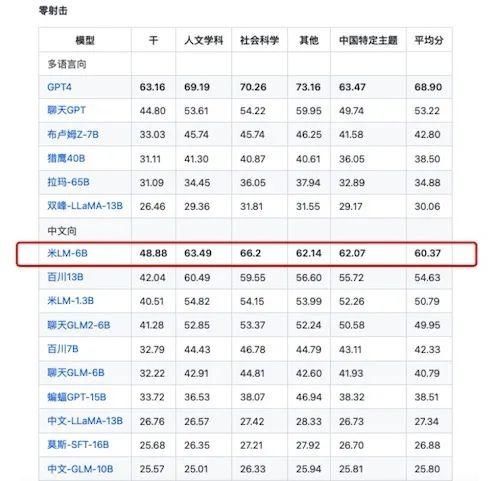
在five-shot测试中,小米大模型在人文学科得分61.12,社会科学得分61.68,其他得分58.84,中国特定主题得分59.39,平均分为57.17。
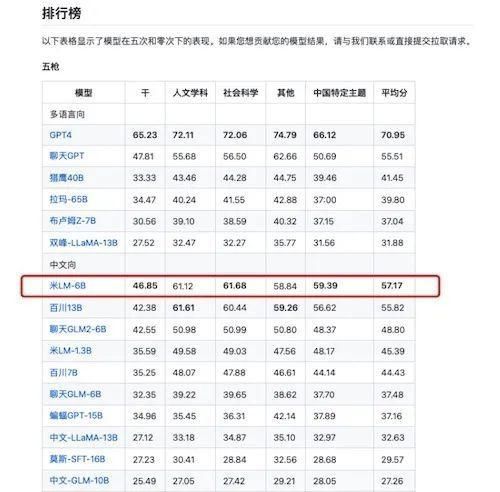
来源:CMMLU截图
来源:微博截图